이번 글에서는 파이썬으로 2주차 학습 내용인 집계 함수, 데이터 요약과 조건문 대한 복습 내용을 작성하겠습니다.
이전 글 링크: https://whda.tistory.com/10
[SQL 입문반 33기] 2주차 복습(Python ver)-1
이번 글에서는 파이썬으로 2주차 학습 내용인 숫자 연산, 연산 함수에 대한 복습 내용을 작성하겠습니다. 데이터 설명이번에도 타이타닉 생존자 데이터를 사용하고자 합니다. 변수명정의Passeng
whda.tistory.com
데이터 설명
이번에도 타이타닉 생존자 데이터를 사용하고자 합니다.
| 변수명 | 정의 |
| PassengerId | 승객 번호 |
| Survived | 생존여부 |
| Pclass | 티켓 등급 |
| Name | 이름 |
| Sex | 성별 |
| Age | 연령 |
| SibSp | 승선 중인 형제나 배우자의 수 |
| Parch | 승선 중인 부모나 자녀의 수 |
| Ticket | 티켓 번호 |
| Fare | 티켓 요금 |
| Cabin | 방 번호 |
| Embarked | 승선한 항구의 이름 |
데이터 출처: 타이타닉 데이터
Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
전체 데이터 일부

1. 집계 함수
아래 코드를 활용하면 대부분의 통계 관련 수치는 확인할 수 있습니다.
titanic_train.describe()
- 개수
Q. Fare 컬럼의 데이터 개수를 구하세요.
# 개수
# 1
titanic_train['Fare'].count()
# 2
len(titanic_train['Fare'])
# 3
titanic_train['Fare'].value_counts().sum()다양한 방식으로 행의 수를 확인할 수 있습니다.
MySQL과 개수가 달라 확인해본 결과 총 개수는 891이 맞습니다.
다만 CSV파일에서 MySQL로 파일을 업로드하는 과정에서 Age컬럼에서 Null인 행 데이터가 삭제되어 올라가는 것을 확인했습니다.
여러 작업을 해봤지만 수정되지 않아 일단 그대로 진행하기로 결정했습니다. 참고 부탁드립니다.
- 합계
Q. Fare 컬럼의 총 합계를 구하세요.
titanic_train['Fare'].sum()
Q. Fare 컬럼의 총 합계를 구하세요.(소수점 첫째 자리에서 반올림하세요.)
titanic_train['Fare'].sum().round(0)
- 평균
Q. Fare 컬럼의 평균을 구하세요.
titanic_train['Fare'].mean()
- 최소
Q. Age 컬럼의 최소값을 구하세요.
titanic_train['Age'].min()
MySQL로 수행했을 때와 결과가 달라 추가로 확인해봤습니다.
원본 파일에도 0.42로 되어 있는 것을 확인했습니다.
MySQL로 파일을 업로드하면서 정수형으로 데이터 타입이 변환된 것 같습니다.
- 최대
Q. Age 컬럼의 최대값을 구하세요.
titanic_train['Age'].max()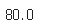
2. 데이터 요약하기
Q. 성별별 티켓 가격의 평균을 구하세요.
titanic_train.groupby('Sex')['Fare'].mean()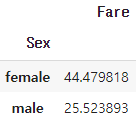
성별을 기준으로 평균 가격을 확인할 수 있습니다.
Q. 성별별 티켓 등급별 티켓 가격의 평균을 구하세요.
titanic_train.groupby(['Sex', 'Pclass'])['Fare'].mean()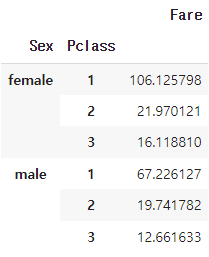
MySQL보다는 시각적으로 보기 더 편하다고 느꼈습니다.
- 조건 추가(HAVING)
Q. 성별별 티켓 가격의 평균을 구하고 평균 티켓 가격이 30이상인 것만 나타내세요.
group = titanic_train.groupby('Sex')['Fare'].mean()
group[group >= 30]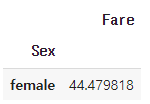
- 정렬 추가(ORDER BY)
Q. 성별별 티켓 등급별 티켓 가격의 평균을 구하세요.(정렬순서: 티켓 등급 오름차순, 만일 같다면 성별 알파벳 오름차순)
titanic_train.groupby(['Sex', 'Pclass'])['Fare'].mean().reset_index().sort_values(by = ['Pclass', 'Sex'])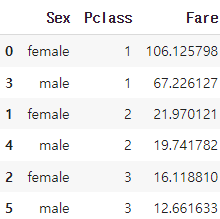
Pclass 컬럼은 만약 내림차순으로 정렬해야 한다면 아래와 같이 작성하면 됩니다.
titanic_train.groupby(['Sex', 'Pclass'])['Fare'].mean().reset_index().sort_values(by = ['Pclass', 'Sex'], ascending = [False, True])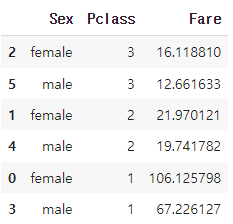
3. 조건문
- CASE문 조건 1개
Q. 나이가 60세이상면 'old'이고 미만이면 'young'인 'age_category' 컬럼을 추가하세요.
titanic_train['age_category'] = np.where(titanic_train['Age'] >= 60, 'old', 'young' )
titanic_train.loc[30:35,['Age', 'age_category']]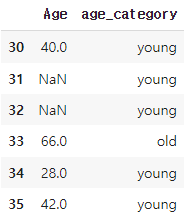
- CASE문 조건 2개 이상
Q. 나이가 19세 미만이면 '미성년', 19이상 40미만이면 '청년', 40세이상 65세미만 '중장년', 65세이상면 '노년'인 'age_group' 컬럼을 추가하세요.
filtered = titanic_train[titanic_train['Age'].notna()]
conditions = [
(filtered['Age'] < 19),
(filtered['Age'] < 40),
(filtered['Age'] < 65),
(filtered['Age'] >= 65),
]
values = ['미성년', '청년', '중장년', '노년']
filtered['age_group'] = np.select(conditions, values)
filtered.loc[24:35,['Age', 'age_group']]
- GROUP BY 추가
Q. 성별별 age_group별 사람 수를 구하세요.(정렬순서: age_group 오름차순, 성별 오름차순)
filtered.groupby(['Sex', 'age_group'])['PassengerId'].count().reset_index().sort_values(by = ['age_group', 'Sex'])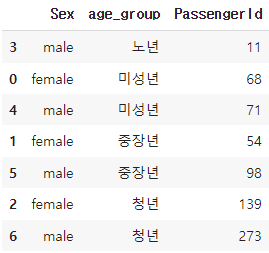
이것으로 파이썬으로 하는 2주차 복습을 마무리하겠습니다.
다음 글에서는 3주차 후기에 대해 작성하겠습니다.
전체 소스코드가 궁금하다면 아래 깃허브 주소를 참고해주세요.
https://github.com/HSYhrae/TIL/tree/master/MySQL/Datarian
TIL/MySQL/Datarian at master · HSYhrae/TIL
Today I Learned. Daily commit. Contribute to HSYhrae/TIL development by creating an account on GitHub.
github.com
본 내용은 데이터리안 'SQL 데이터 분석 캠프 입문반' 을 수강하며 작성한 내용입니다.